5 Methods to View a Page as Googlebot


Google’s AI experiences are expanding rapidly – with the rollout of AI Mode in the US this June and AI Overviews showing for more and more search queries. Although Google's organic search landscape is changing, many SEO fundamentals are still the same.
If you want your site to be indexed, ranked, and cited in the search results – and within AI experiences – it’s important to make sure Googlebot and other search engine crawlers can not only access your pages, but also access the content within those pages.
If Googlebot or Bingbot can’t access content on a page, it can’t be cited in places like AI Overviews, AI Mode, or Copilot.
In my experience, I have most often seen this issue on blogs, where links to individual posts weren’t accessible to search engines. I’ve also seen it happen on ecommerce sites where links to Product Detail Pages (PDPs) weren’t accessible from Product Listing Pages (PLPs).
In these instances, it’s harder for search engine crawlers to discover links to these individual pages to crawl and index or cite them – especially if they aren’t included in the sitemap.xml file (which they should be!) or linked from other pages on the site.
If you suspect Googlebot can’t access some of the content on your webpage, I’ve outlined five different ways to help you see your site the way Googlebot sees it. I usually like to use several of these methods together just to make sure I’m getting the same results across the board.
A quick disclaimer – Cypress North has not created any of these tools or methods, but we have found them useful and wanted to share them with our readers.
Let’s get into it!
Method 1: Google Search Console
Google Search Console is a free tool marketers universally should have access to. Aside from viewing organic search performance data, you can also inspect URLs individually to check for indexing issues, either by requesting information from the Google Index or by running a live test.
Requesting information from the Google Index will let you see why a URL was or wasn’t indexed at the time it was crawled. This is helpful for identifying if a URL isn’t indexed because of a noindex tag, a canonical, or if the URL can’t be crawled because it’s blocked in the robots.txt file. You can also see where Googlebot discovered your URL from (if it found the link from a sitemap, an external website, etc.).
But if you want to see how Google sees your page now, you need to run a Live Test. To do this:
- Inspect the URL you want to see either by using the search bar at the top of the platform or from a Performance or Indexing report

- Once you’ve inspected that URL, select “Test Live URL” in the upper right corner of the Google Search Console platform:
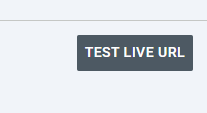
- Once the test has completed, click on “View Tested Page” to open a window with the page’s HTML, a screenshot of the page, and additional information about the page, like the content type and HTTP response.
If elements of your page are missing from the rendered screenshot, it may be because resources are blocked to Googlebot. You can see which resources were blocked by clicking on the “MORE INFO” tab next to “SCREENSHOT”.
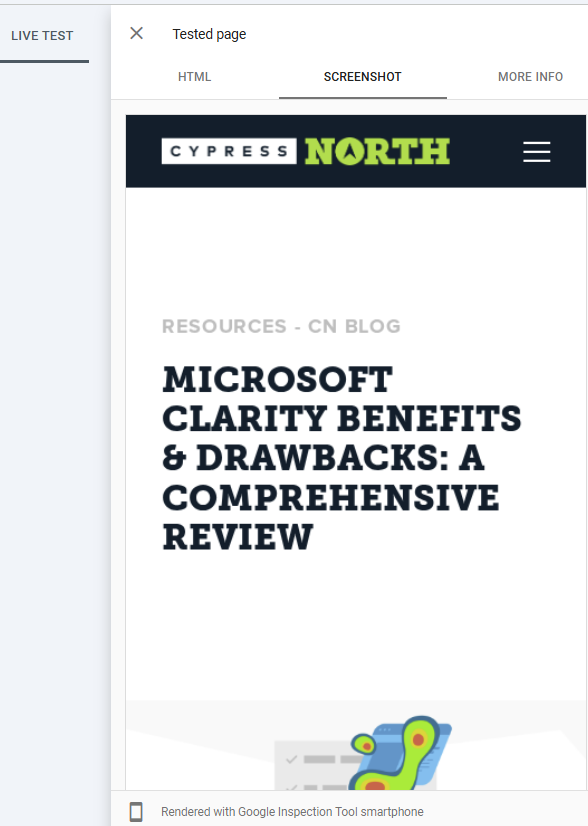
Pros of Google Search Console’s Live Testing Tool
- Like most of the other methods featured in this post, Google Search Console is free.
- Data from the Google Index is coming directly from Google itself, not a third party. So if you want to see what Googlebot sees, this is the place to start.
Drawbacks:
- You can only test one URL at a time.
- Google Search Console limits the number of live tests you can run per day, per property.
Method 2: To The Web Googlebot Crawling Simulator
The To The Web tool is super easy to use. Just input the URL in question into the search bar and the tool will return all of the text and on-page links that are accessible to Googlebot.
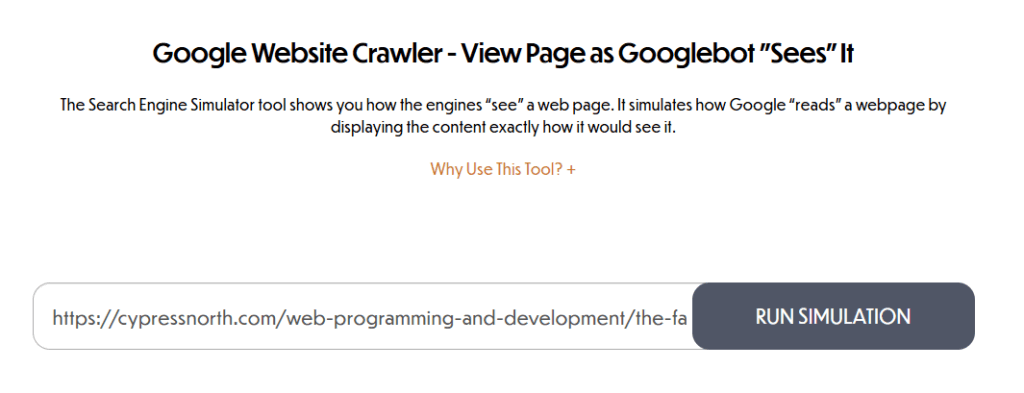
Pros of the To The Web Googlebot Crawling Simulator:
- This tool shows both text and links that are accessible to Googlebot.
- The To The Web Google Website Crawler is very visual, so if you’re explaining the problem to someone, this tool makes it easy to see what’s accessible to Googlebot and what’s not.
- This tool goes beyond Googlebot accessibility and shows keyword frequency, headings, the title tag, meta description, etc.
Drawbacks:
- This tool doesn’t allow you to check URLs at scale – you can only input one URL at a time.
- This tool only shows you how Googlebot sees your page, not any other search engine crawler.
Method 3: Screaming Frog
Screaming Frog can be used for a million different things and is a staple in the SEO tool chest. If you haven’t used this tool before – at a very high level, you input a website URL into Screaming Frog and it will crawl links from that URL to find a website’s linked pages and external links. From there, you can find SEO issues that could be affecting your site, export URLs, find broken links, etc.
By default, Screaming Frog uses the Screaming Frog SEO Spider user agent, but this can be changed to user agents for Googlebot, Bingbot, Yahoo-Slurp, DuckDuckBot, and more.
If you want to see if you have a Googlebot accessibility issue, you could change your user-agent by going to Crawl Configuration > User-Agent > and then selecting the user agent you’d like to crawl with in the dropdown. Since Google uses mobile-first indexing, I would start with Googlebot Smartphone.
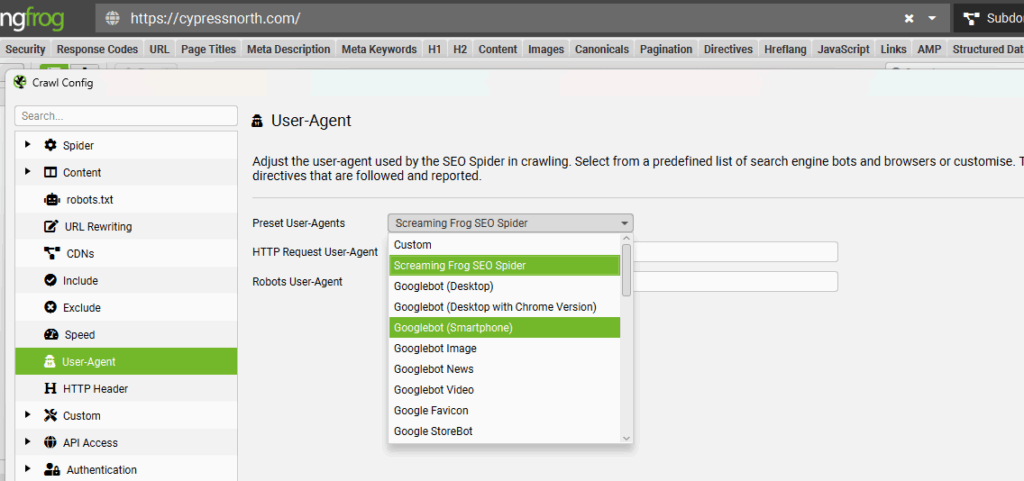
From there, you just input the URL or website domain you’d like to start with and let Screaming Frog run until the crawl is completed.
If you have a situation where, for example, you think Googlebot can’t access links to individual blog posts from your blog, start by finding the main blog page in the Screaming Frog crawl and select it. Then view “Outlinks” in the section at the bottom of the tool to see what links Screaming Frog found from that main blog page. If it’s not pulling in any individual blog post URLs, that might be a sign that Googlebot isn’t able to access links to your blog posts from the main blog page.
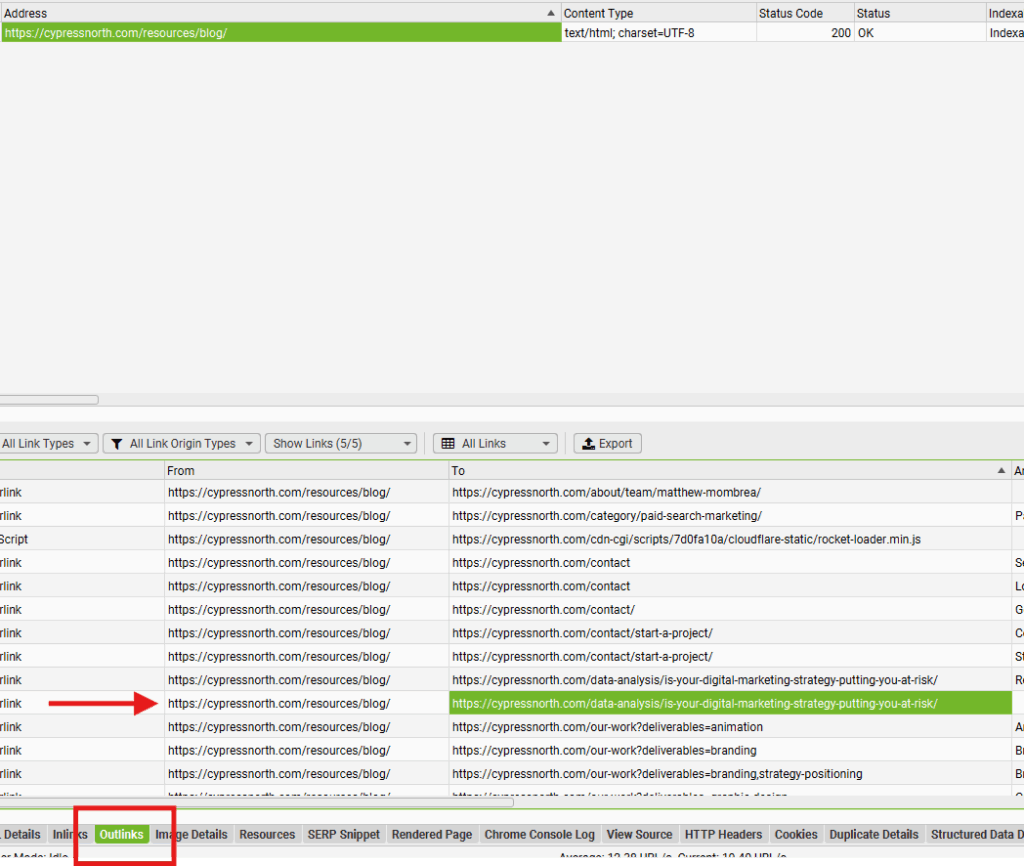
You could also reverse the process slightly by selecting an individual blog post URL, then viewing “Inlinks” to see the pages where Screaming Frog found a link to that blog post URL. If Screaming Frog didn’t find the post as an inlink from the blog, that could be a sign that Googlebot can’t access links to your individual posts from your blog.
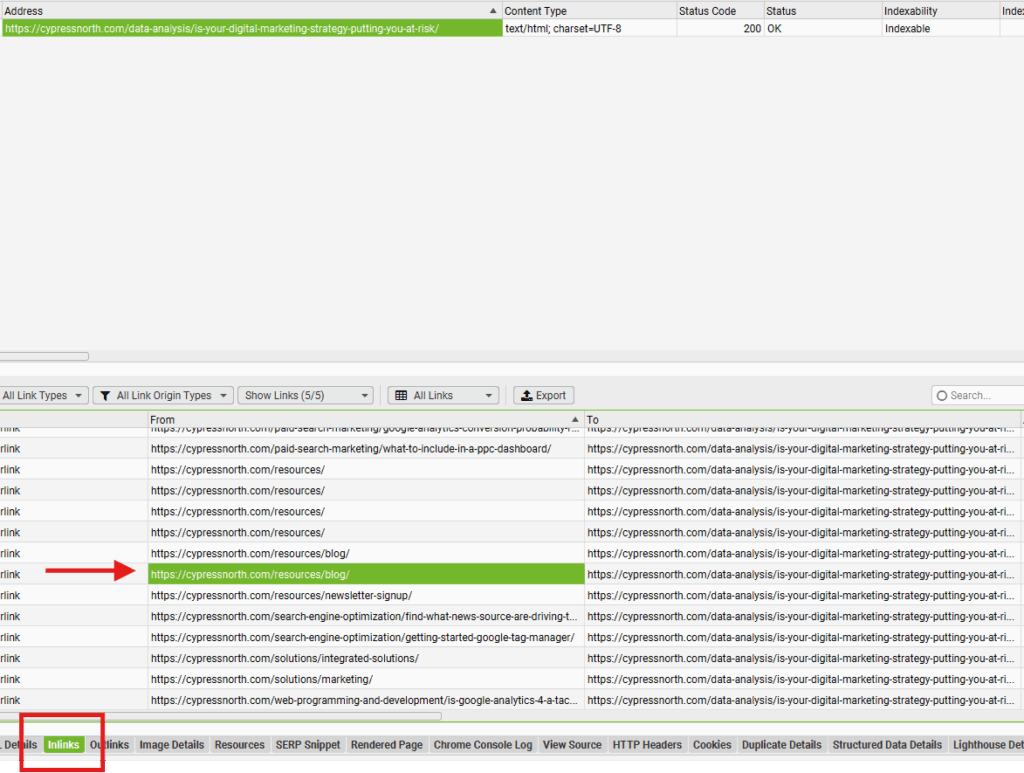
Pros of Screaming Frog:
- Screaming Frog allows you to look at pages at scale, so you can view multiple URLs at once.
- The Screaming Frog user agent can be changed for any search engine crawler.
- The Rendered Page tool will let you see how a page is rendered as Googlebot (or another crawler) when JavaScript Rendering is enabled and the user-agent you need is configured.
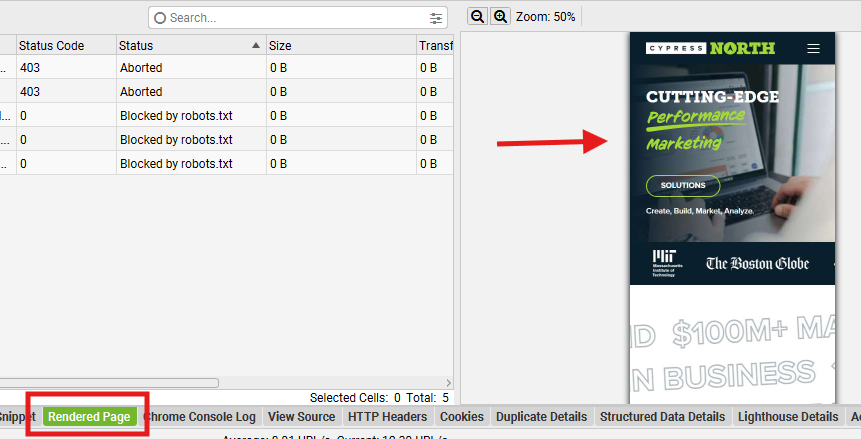
Drawbacks:
- A paid license is required to crawl a site with more than 500 URLs. If you attempt to use the free plan on a site with more than 500 URLs, Screaming Frog won’t be able to complete the crawl, making the results unreliable.
Method 4: Dentsu Fetch & Render
Like Method 1, Dentsu Fetch & Render is very easy to use – you just input the URL in question, select your user agent, configure the settings, then run your test.
Pros of Dentsu’s Fetch & Render Tool:
- You can choose between different user agents.
- The tool will show you what URLs couldn’t be accessed and which are blocked from crawling:
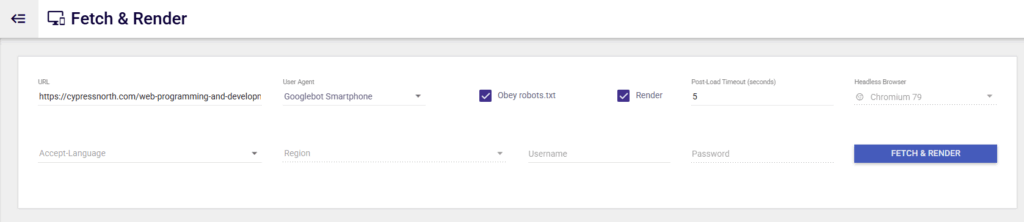
- A screenshot of the rendered page is shown, similar to Screaming Frog and Google Search Console.
Drawbacks:
- URLs must be tested individually.
Method 5: Tutorial from gentofsearch.com
This tutorial, written by Adam Gent of gentofsearch.com, shows you how to use Chrome Canary to make your own Googlebot crawler. The end result is very visual, which makes it a great way to explain the issue to someone who may not be familiar with how search engines render website content.
For more details, view the tutorial here.
How to Fix Googlebot Accessibility Issues on Your Website
Now that we’ve covered four different ways to see your site as Googlebot – what’s next? If you’ve tried these methods and think your content isn’t accessible to search engine crawlers, it’s time to identify what’s happening.
Matt, our Chief Technology Officer, identified two common causes of these accessibility issues below.
Cause #1: Blocking Crawlers
This one may be obvious, but it’s worth double-checking. If you’ve created a robots.txt file, review it to make sure you’re not unintentionally blocking pages from being crawled.
Additionally, individual pages could potentially be blocking crawlers – either through a manually added meta tag, or using a plugin like Yoast.
Finally, if your website is behind a firewall or security system like Cloudflare, ensure that good bots are being allowed through to your site for crawling and indexing.
Cause #2: Client-Side Rendering
With the recent popularity of “headless” content management systems and ecommerce platforms, client-side rendering has become a big problem for SEO. This is largely a software development problem where programmers utilize a technique without understanding how it impacts search crawlers and indexing.
Traditionally, when a visitor or crawler comes to your website, their browser makes a request to your server. Your server then renders the complete HTML for your page, including dynamic content, and returns it to the visitor, where it’s displayed in their browser (I’m simplifying). This is known as Server-Side Rendering (SSR).
With Client-Side Rendering (CSR), when a visitor or crawler makes a request to your server, the server responds with a mostly empty HTML file that includes links to JavaScript files, which contain data and instructions for how the visitor’s browser should render the page. This often includes downloading and rendering parts of a page once interacted with, not on initial load.
The issue with CSR when it comes to search engine crawlers is that, even though most can execute JavaScript, the crawlers are designed to move from page to page very quickly. When a crawler receives the mostly empty response from the server, it will find little to no content to index and may move on before the linked JavaScript data is ever downloaded or rendered. Additionally, if certain page elements like a main navigation menu are only populated on a click or hover, the content inside the menu will not be indexed or crawled, as that content will be invisible to the crawler.
While there are solutions to develop client-side rendered sites properly for SEO, developers don’t always have that in mind or understand the impact of their tools. Some modern frameworks like Next.js or Nuxt have a variety of rendering modes, and they need to be carefully considered.
Development teams also need to be more considerate of SEO implications when they are programming a site using a frontend framework. For example, simply calling the useEffect() function in Next.js will make a component become client-side rendered, even if that wasn’t the intention.
If you suspect your website has rendering issues like the above, but aren’t sure how to identify them or implement a solution, get in touch with our SEO and development teams. We’ll help you get to the bottom of it!
Meet the Author

Kathleen Hagelberger
Kathleen is our Director of Organic. She joined Cypress North in July 2019 and works out of our Buffalo office. Known by coworkers and clients alike as Kbergs, Kathleen is an SEO specialist who brings more than four years of experience to our digital marketing team. Some of her daily responsibilities include monitoring organic traffic for clients and reporting on what she finds, putting together site plans, helping with new site launches, project management, and other SEO projects. She also makes occasional guest host appearances on our Marketing O’Clock podcast.
Before joining Cypress North, Kathleen gained professional experience through internships with Genesee Regional Bank and TJX Companies, Inc. She has earned her Google UX Design certificate, Google Analytics 4 certification, and HubSpot Content Marketing certification.
Originally from Attica, Kathleen graduated from the Rochester Institute of Technology with bachelor's degrees in new media marketing and management information systems.
Outside of work, Kathleen is on the volunteer committee for Erie County's Walk to End Alzheimer's chapter. She also serves as the Vice President of Public Relations for one of the Buffalo chapters of Toastmasters.
In her downtime, Kathleen enjoys taking dance classes like tap and jazz and fitness classes in general. She also likes going to the beach, trying new restaurants, reading, watching 80s movies, and Marie Kondo-ing her apartment.
Related Resources

3 Options for Multilingual Website Translation
Managing multilingual web content is challenging, and there are plenty of options available. Learn more about the solutions and how to find the right one for you.
Google Launches AI Mode: What it Means for the Future of Search
Google’s new AI Mode marks a major shift in its search strategy. Here’s how we expect it to transform the user experience and future of search.

13 Digital Marketing Predictions for 2025
Top Industry Voices Share Their 2025 Digital Marketing Trend Predictions As digital marketers, we know a new year brings new goals, new opportunities for growth, and new challenges. But a new year also brings plenty of change. Whether it’s advancements […]

Let's Put a Stop to Google Page Annotations
Google's Page Annotations will direct some visitors away from sites and back to search. We’re calling for an end to this practice.

Choosing the Right Digital Marketing Career Path as a New Marketer
Learn more about the different career opportunities in digital marketing by exploring the roles of SEO and PPC specialists. Gain insights into key skills, tools, and strategies to help you determine the best path for your professional career.

6 SEO Tips & Tricks We Learned at WTSFest 2024 in Philadelphia
Three of our digital marketers recently picked up some new tips, tricks, and best practices at the 2024 Women in Tech SEO Festival. Learn more about what we learned and how we’re applying it to our work.

How to Create a Looker Studio SEO Report Without Paid Connectors or Expensive Subscriptions
Effectively Measure Organic Traffic Performance With an Easy-To-Create Dashboard Measuring organic traffic performance is a key part of SEO. But with so many different metrics available to track, it can be challenging to know what data to look at when […]

Testing Website Accessibility: Five Testing Tools & Methods To Identify Accessibility Issues
Is your site compatible with website accessibility guidelines? Use these tools to benchmark and identify improvement opportunities. Website accessibility is often overlooked, but it shouldn’t be. According to CDC estimates, 61 million adults in the United States alone live with […]

23 Of The Best Resources For Starting A Digital Marketing Career
The best social media communities, podcasts, newsletters, and certifications for new digital marketers I didn’t know anything about digital marketing when I started as an intern at Cypress North earlier this year. Acronyms like SEO, CPA, and ROAS meant nothing […]

A Marketer’s Website Launch Checklist
SEO, Google Tag Manager Tracking, & Content Planning for a New Website There’s nothing quite like launching a beautiful, brand new website, but it is something that can have ugly consequences if not performed correctly. While marketers aren’t typically responsible […]

SEO for PDFs - How To Optimize PDFs For The Web
Let’s face it, for some companies Portable Document Formats (PDFs) are an unfortunate necessity. From sell sheets and downloadable product flyers, to manuals and tutorials - PDFs have secured a spot in our lives, and there are some tips and […]

Updated: How To Exclude Mobile Apps From Google Ads Display Campaigns
If you’ve been following us for a while, you’ll know we generally don’t like running ads on mobile apps. Don’t get us wrong, we love apps! They’ve made it easier than ever before to get information and connect with each […]

Digital Marketing in 2019: What to Watch For
The Pros Rampant Responsive One of the biggest boons for advertisers in 2018 was the ability to optimize campaigns by moving away from standard banner sizes and utilizing responsive display ad formats. The proliferation of flexible ads such as Facebook […]

Firing Up Bing Ads? Crucial Differences Between Bing & AdWords To Consider When Setting Up Your Campaigns
Does Anyone Even Use Bing? As digital marketers we tend to hear this question on a weekly basis, if not more often. And while the mere idea that Bing exists is enough to shatter the worldview of many Google nerds/religious Chrome users, the […]

Getting Started With Google Tag Manager
What is Google Tag Manager? Google Tag Manager (GTM) is a tool that gives users a way to add code to a website without having to log in to the backend and manually add to the source code every time. […]

The Retargeting Playbook: The Ultimate Guide To Setting Up Successful Retargeted Ads
As an internet user, you’ve likely become accustomed to those ads that seem to follow you during all your digital travels. These ads are known as “retargeted” ads (or “remarketed” ads if you're using Google) and help to keep your […]

How to Connect Your Google+ Business Page to Your Local Places Listing
The time has come -- Google is finally allowing users with Google+ Business Pages to connect the page with the Google+ local listing (also known as Google Places) on Google Maps. Confused already? Yeah, us, too. But we'll save that […]

How To Link (Many) AdWords Accounts with Google Analytics Using The New Bulk Account Linking Option
All of you pro AdWords users who routinely take on clients with many AdWords accounts for different promotions can breathe a collective sigh of relief. This week Google came out with a simple way to connect AdWords and Analytics in bulk! […]

Keyword Research Tips: How To Use Bing Ads Editor To Estimate Positional Volume & Pricing
If you are a search pro using Bing, you'll likely spend a good chunk of time living in the Bing Ads Editor. Much like Google's AdWords Editor, this standalone desktop program saves advertisers time and energy by allowing for bulk […]
How To View Geographic & Location Data Directly Within Google AdWords
When it comes to AdWords, all locations are not created equal. It's important to track which locations are converting -- and which aren't. With AdWords, you can increase or decrease bids based on the location you're targeting, and diving into […]