Python & Google Analytics: Prepare Data For Analysis [ Jupyter Notebook Template]

To utilize the power of Python to manipulate and analyze your Google Analytics data, the first step is to transform your data into a clean DataFrame that’s ready for analysis. In this article, I’m going to show you how to do just that. After reading, you’ll be ready to get your data out of Google Analytics, into a Jupyter Notebook, and ready for analysis in any way you please!
You’ll learn:
- How to export your data from Google Analytics
- How to open your Google Analytics data in a Jupyter Notebook
- How to remove data that you don’t want
- How to avoid/resolve errors you may get along the way
Plus, we’re including a downloadable Jupyter Notebook template that contains all the code we’ll cover in this article.
Note: There are other ways to go about it than described in this article that involve the Google Analytics API, but if you don’t have experience working with the API, the methods that we’ll cover are the easiest and quickest.
Step 1: Create your report in Google Analytics
Any built-in or custom report that you can export as a CSV or XLSX will work. For this example, I’m using the Location report from the Audience section.
Before you export, make sure all rows are selected at the bottom - only the rows that are showing will export.
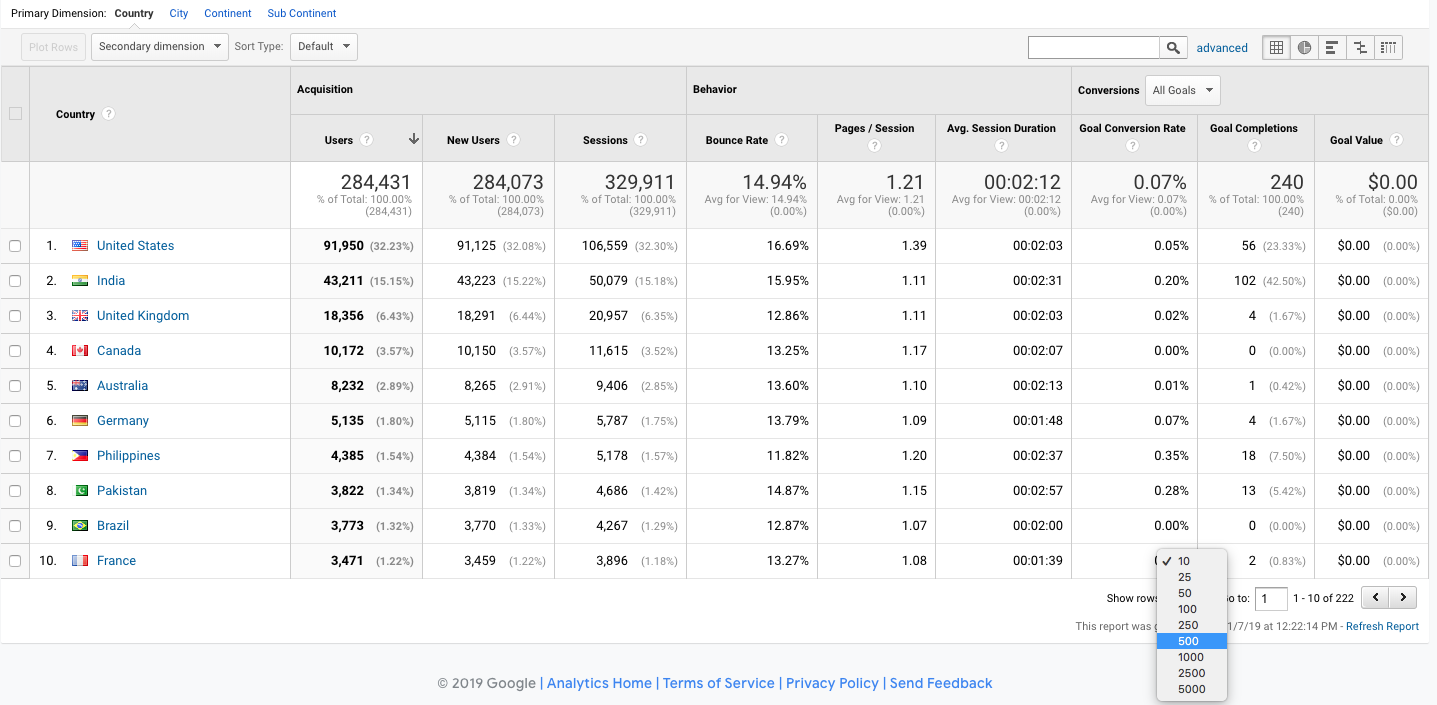
Now that I’m seeing all 222 rows, I’m ready to export! Choose a CSV or XLSX.

Tip: Make sure your date range is set appropriately and add in a secondary dimension that’s helpful to you if you need it.
Step 2: Open up a new Jupyter notebook
It’s important that you open your new notebook in the same place that you saved your Google Analytics file or else you’ll get an error saying your file doesn’t exist when you’re trying to open it.
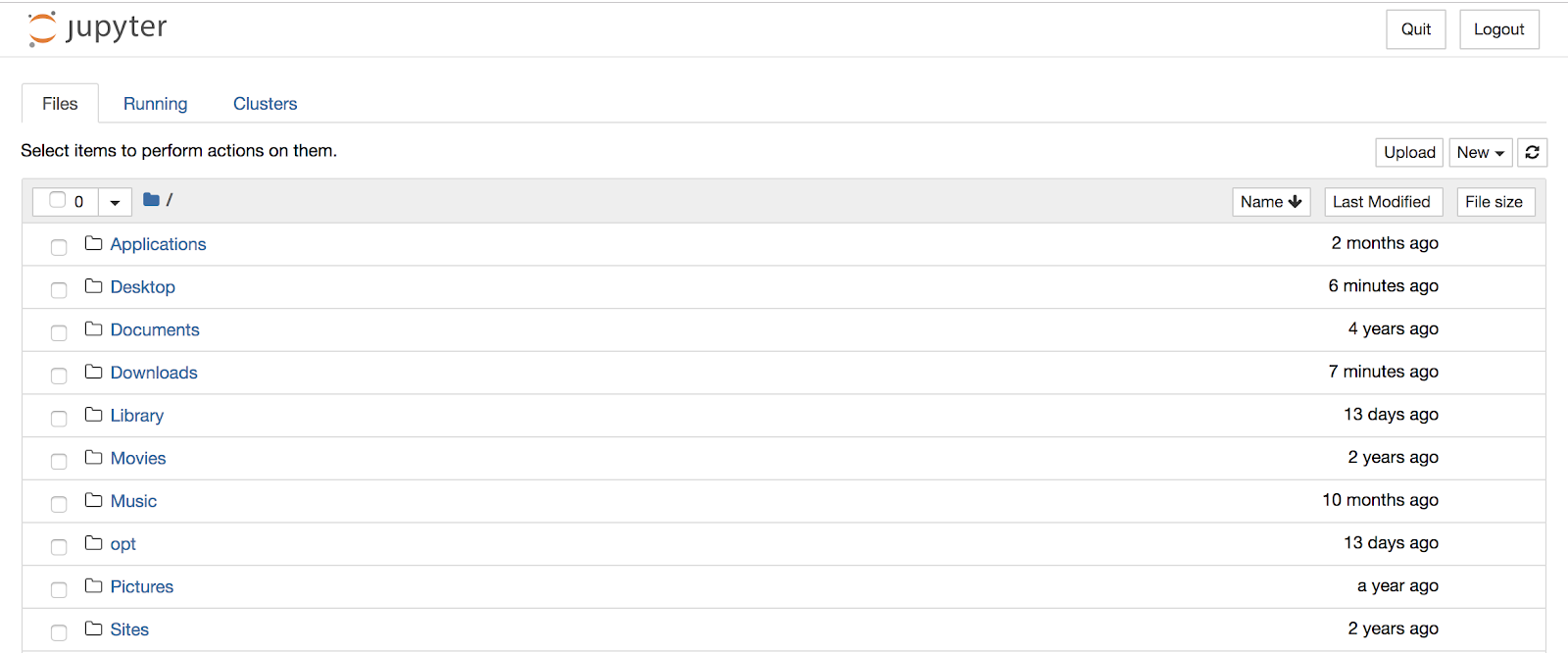
My Google Analytics CSV is on my desktop so I’m going to click into Desktop first and then open up a new Python 3 notebook.

Step 3: Import Packages
In your first cell, import the Python library, pandas.
import pandas as pd
The pd portion is arbitrary and can be called whatever you want to refer to pandas as. But you’ll need to call this later, so naming it having something short and intuitive is helpful.
This is the only package that you’ll need to open your file, see it in a clean DataFrame format, and do some simple cleaning. You may want to import other packages depending on what type of analysis or visualization you want to do later - feel free to add those in here.
Step 4: Open Your CSV or Excel file
The code you’ll enter for this step will be slightly different depending on if you are opening a CSV or XLSX file.
To open a CSV, enter the following in your next cell
GA_Location = pd.read_csv('GA-location-data.csv', skiprows=5, skipfooter=495)
You may get the following error when you run this cell:

If you do, edit your code to include this last engine=’python’ piece.
GA_Location = pd.read_csv('GA-location-data.csv', skiprows=5, skipfooter=495, engine='python')
Let’s dissect this:
GA_Location - This is the variable I’m setting the function after the equals sign to so I can call my DataFrame anywhere in my Jupyter Notebook. You can name your variable whatever you want that makes sense for your dataset.
pd.read_csv - This is using the pandas library (Remember, in my first cell I stated that I’ll be calling pandas with “pd”) to open the CSV.
'GA-location-data.csv' - This is what I named my CSV on my desktop. Replace this with the name of your file. And again, remember to save to the same location as you opened your Jupyter Notebook or you will get an error after running this cell.
skiprows=5 - There is some extra information that Google Analytics puts in the CSV file that isn’t part of your dataset. If you open up your CSV, you’ll see it in the first few rows:
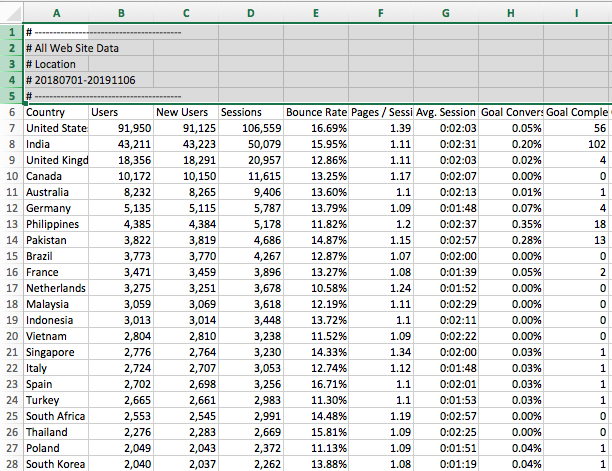
This piece of code disregards those rows. Without this, you’ll get an error when you run your cell.
skipfooter=495 - There is more unnecessary information that Google places that the end of the file. This will skip the rows at the bottom that aren’t part of your dataset. The number that you enter is the total number of rows at the end that you want to disregard. In my file, it was rows 230 through 725, which gave me 495.

To open an Excel file, enter the following in your next cell:
GA_Location = pd.read_excel('GA-location-data.xlsx', sheet_name='Dataset1')
Let’s dissect this:
GA_Location - This is the variable I’m setting the function after the equals sign to so I can call my DataFrame anywhere in my Jupyter Notebook. You can name your variable whatever you want that makes sense for your dataset.
pd.read_excel - This is using the pandas library (Remember, in my first cell I stated that I’ll be calling pandas with “pd”) to open the Excel file.
sheet_name=’Dataset1’ - If you open up your Excel file, you’ll notice that there are 3 tabs, but only one of them has the dataset that you actually wanted to export. I’m identifying the name of this tab here, ‘Dataset1’. Feel free to change the name and edit this piece of code to match if you’d like.
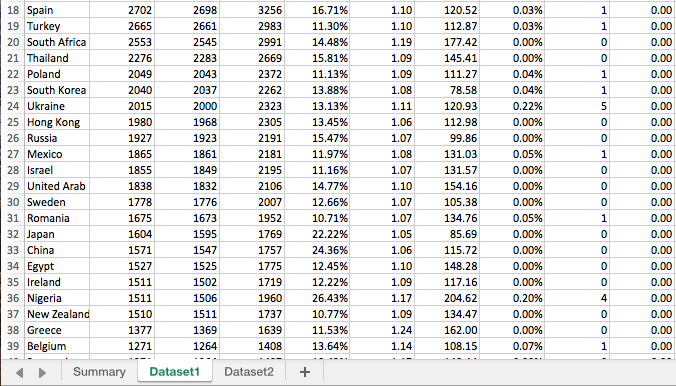
If you didn’t already, run your cell. You shouldn’t see any output yet - but as long as you don’t get any errors or warnings, you’re ready to move on to step 5.
Step 5: Let’s see the data!
This is where our variable (In my case, GA_Location) will come in handy. Enter your variable name with .head() after it in the next cell. This will show us the first five rows of data so we can make sure it looks as we expect it to without getting a super long list of all the data.

Let’s also take a look at the bottom of the DataFrame - especially if you opened a CSV, we want to make sure all the unnecessary information that Google Analytics added to the bottom is gone. We can change .head() to .tail() to see the last five rows:

Tip: If you want to see more than 5 rows at the bottom or top, you can add any number into the parenthesis. For example, changing it to .tail(15) shows me the last 15 rows:

Step 6 (Optional): Drop rows that contain missing values
There may or may not be certain rows that you want to drop to achieve your perfect dataset starting point. These may be rows that contain:
- (not set)
- NaN
Depending on your analysis goals, you may want to drop some, all, or none of these. For example, from the last screenshot above, it looks like the last row that has NaN in the Country column is a row that sums all the values in my columns. If I’m planning on making my own sums with different combinations of data, I likely don’t want this row to be mixed in and I should drop it.
I can simply do this with the following:
GA_Location.dropna(inplace=True)
The inplace=True piece is what will save your DataFrame into a new version with the rows that contain NaN values dropped. If you don’t include this piece and you call your variable again, it will still return your old DataFrame.
With that said, if you don't want to permanently change your DataFrame, you can simply take this out and leave the parenthesis empty.
Now if I search for rows that contain NaN values, I do not get any results which means they’ve successfully been removed:

Removing rows with (not set) is also a choice dependent on your goals. For example, if I want a list of all the unique countries in my dataset, having (not set) would be useless and I should remove it. However if I’m only concerned with the metric data, I would keep it since there would still be metric values for my (not set) row.
If you want to remove (not set) rows, enter the following code, replacing ‘Country’ with the dimension in your report:

This shows me that row 56 contains (not set).
You can drop a single row by identifying it with the row number, in this case 56:
GA_Location.drop(GA_Location.index[56], inplace=True)
Again, we’re using inplace=True to overwrite the DataFrame so it saves our change of dropping row 56.
Now if I check for (not set) values again, I see that it’s successfully been removed.
GA_Location.head(60)
While this is a simple solution to remove one row, you may have cases where you need to remove a bunch of rows that have (not set) or any other particular value. In this case, you can use the following method that is more inclusive:
GA_Location = GA_Location[GA_Location.Country != '(not set)']
Here, I'm overwriting my DataFrame by setting it to my same variable name, GA_Location. This will create a new DataFrame that only contains rows where ‘Country’ does not contain (!= translates to ‘not equal to’) ‘(not set)’
Again, if I look for (not set) values after running this, I do not get any results which means they’ve been removed!

The data is your oyster!
After following these steps, you should have clean Google Analytics data set up for any type of manipulation and analysis. You might want to filter and sort data, combine this data with other datasets (from Google Search Console, Screaming Frog, or anywhere really) to make custom reports, create graphs and other visuals quickly, automate arduous tasks...you get the idea!
What will you do with your data? We want to hear about it! Let us know how you use Python with Google Analytics data in the comments. Be sure to subscribe to our newsletter so you don’t miss other data and analytics tutorials, tips and tricks just like this one.
Download the free Jupyter Notebook template
Ready to prepare your data for analysis? Download and follow the instructions to easily alter the code to your needs.
Related Resources
Is Your Digital Marketing Strategy Putting You at Risk? Understanding CCPA’s New Legal Precedent
Capital One’s privacy lawsuit highlights growing risks for marketers relying on standard tracking technologies. Here's what you need to know.

Using BigQuery to Overcome GA4 Data Retention Limits
Keep your GA4 data forever with BigQuery. Learn how to set up BigQuery to start storing raw GA4 data before it's gone for good.

Why US Businesses Need to Prioritize Data Privacy Now
The U.S. doesn't have a comprehensive national data privacy policy in place, but that doesn't mean businesses aren't being impacted. Learn more about the state-level policies reshaping digital marketing strategy and compliance.
![Data - Blog - Google Collab [Background]](https://cypressnorth.com/wp-content/uploads/2024/03/Data-Blog-Google-Collab-Background-640x360.jpg)
How to Get Started Using Python for Data Analysis in Google Colaboratory
Learn how to use the free Google Colab tool and perform data analysis with Python programming language in this tutorial for digital marketers and data analysts.

How to Save Universal Analytics Data
All historical data from Google’s Universal Analytics will be deleted on July 1, 2024. Learn more about what your options are for backing it up before it’s gone for good.

Is Google Analytics 4 a Tactical Move Away From Free Analytics?
There’s something fishy going on with the way that Google is handling GA4. To me, it’s playing out as a backdoor cash grab, hidden under a thin veil of a free and easy migration from UA.
Data Lakes & Data Warehouses: What Are They? (& Why Your Company Probably Needs Both)
Data lakes and data warehouses have gained increased interest from organizations in recent years for their ability to support a single source of truth for data-driven decision-making across various departments. Understanding the strengths and applications of each is important not […]

How to Get Started with GA4: A Step-by-Step Guide
Need help setting up GA4 for your company or client’s website? Look no further! This post provides a step-by-step process for creating GA4 properties and best practices to make sure necessary events are tracked and the data flowing into GA4 are accurate.
How To Change Your Google Analytics Attribution Model in GA4
One of the biggest changes to Google Analytics has arrived in 2022 - the ability to change your Google Analytics attribution models. This is a first for Google Analytics as this attribution model change will not just apply to a […]
Why You Should Set Up Google Analytics 4 Today
Let's face it. GA4 isn't GR8. Google Analytics 4 is a work in progress to put it kindly. However, in these final weeks of 2021 you have an opportunity to get GA4 installed and tuned up, giving your future self […]

What to Include in a PPC Dashboard
Learn What Metrics to Include in PPC Reports. Then, Download Our Free Data Studio Dashboard Template! Let’s be real, pay per click advertising is all about data. What campaigns are bringing in the most revenue? What landing pages are converting […]

6 Google Ads Custom Columns to Help Uncover More Data
You may already know you can create custom columns in the Google Ads online interface. But, if you're anything like me, you may not always think about how you can leverage custom columns to surface essential Google Ads performance metrics, […]

How To See Audience Performace Across Campaigns With Google Ads Reports
Google Ads makes it really easy to see performance at the campaign or ad group level, but analyzing audience performance across multiple Google Ads campaigns is easier said than done. You're left wondering.... What's working well? What's not? Combining like-minded […]

Install Google Analytics on Web Stories With the Official WordPress Plugin
You read that right - the moment we've all been waiting for is here! Google’s Web Stories plugin is out of beta and now offers the ability to install Google Analytics on Web Stories directly in the plugin. If you […]
Cross-Domain Tracking With Google Tag Manager: A Simple Guide
Cross-domain tracking can make your life a lot simpler if you find yourself having to analyze Google Analytics data from two different sites. It allows you to capture the full user journey from the moment they land on one domain […]

Why Don't Multi-Channel Funnel Reports Match Up With Other Reports in Google Analytics?
Why don't numbers from the multi-channel funnel reports match up with numbers for the same metrics in other Google Analytics reports? The discrepancy is largely due to differences in what Google considers direct traffic. Read our guide to gain a full understanding of attribution differences in Google Analytics reporting.

Exploring a New Dataset With Python Part II: Using Seaborn To Visualize Data
Welcome to Part II of Exploring a new dataset with Python! If you missed Part I: The Basics, you can check it out here. In this article, we’ll be returning to our animal mug company’s dataset to continue our exploratory […]

Exploring a New Dataset With Python: Part I
We’re taking it back to the basics in this article. Why? The day of a Digital Marketer is busy. We’re pulled in all sorts of different directions and are responsible for a lot of different things. In my personal experience, […]

Strip Query Strings From URL Data: Python For Digital Marketing
If you’ve ever spent any time in a Google Analytics account, you’re all too familiar with the fact that the data isn’t always pretty. One exceptionally common scenario that us marketers run into all the time is page data being […]

Pandas Groupby Function: Python for Digital Marketing
If you’ve been following along with our Python for Digital Marketing posts, you’ve imported data from Google Analytics into a Jupyter Notebook and may have even combined it with another dataset. If you’ve never been here in your entire life […]